时光漫步
资源详情
Python极简讲义:一本书入门数据分析与机器学习(博文视点出品)

书籍详情介绍






书籍资料
- 内容简介
- 作者介绍
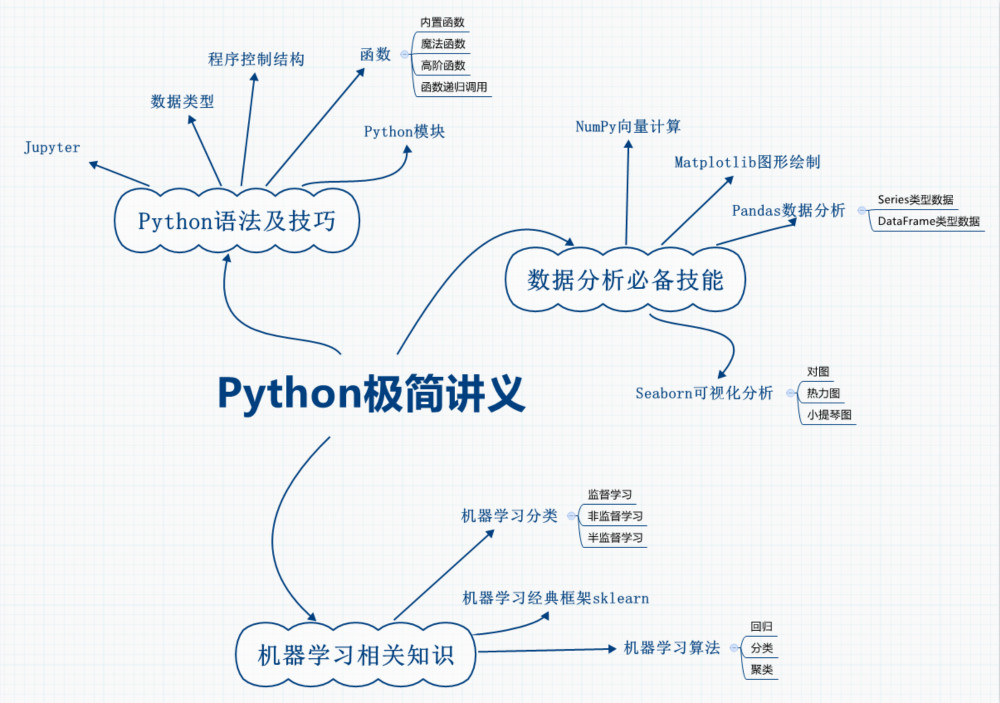
- 书籍目录
本书以图文并茂的方式介绍了Python的基础内容,并深入浅出地介绍了数据分析和机器学习领域的相关入门知识。
第1章至第5章以极简方式讲解了Python的常用语法和使用技巧,包括数据类型与程序控制结构、自建Python模块与第三方模块、Python函数和面向对象程序设计等。第6章至第8章介绍了数据分析必备技能,如NumPy、Pandas和Matplotlib。第9章和第10章主要介绍了机器学习的基本概念和机器学习框架sklearn的基本用法。
对人工智能相关领域、数据科学相关领域的读者而言,本书是一本极简入门手册。对于从事人工智能产品研发的工程技术人员,本书亦有一定的参考价值。
张玉宏,大数据分析师(高级),2012年于电子科技大学获得博士学位,2009—2011年美国西北大学访问学者,2019—2020年美国IUPUI高级访问学者,YOCSEF郑州2019—2020年度副主席。现执教于河南工业大学,主要研究方向为大数据、机器学习。发表学术论文30余篇,先后撰写《深度学习之美:AI时代的数据处理与最佳实践》《品味大数据》等科技图书7本,参与编写英文学术专著2部。
第1章 初识Python与Jupyter 1
1.1 Python概要 2
1.1.1 为什么要学习Python 2
1.1.2 Python中常用的库 2
1.2 Python的版本之争 4
1.3 安装Anaconda 5
1.3.1 Linux环境下的Anaconda安装 5
1.3.2 conda命令的使用 6
1.3.3 Windows环境下的Anaconda安装 7
1.4 运行Python 11
1.4.1 验证Python 11
1.4.2 Python版本的HelloWorld 12
1.4.3 Python的脚本文件 13
1.4.4 代码缩进 15
1.4.5 代码注释 17
1.5 Python中的内置函数 17
1.6 文学化编程—Jupyter 20
1.6.1 Jupyter的由来 20
1.6.2 Jupyter的安装 21
1.6.3 Jupyter的使
23
1.6.4 Markdown编辑器 26
1.7 Jupyter中的魔法函数 31
1.7.1 %lsmagic函数 31
1.7.2 %matplotlibinline函数 32
1.7.3 %timeit函数 32
1.7.4 %%writefile函数 33
1.7.5 其他常用的魔法函数 34
1.7.6 在Jupyter中执行shell命令 35
1.8 本章小结 35
1.9 思考与提高 36
第2章 数据类型与程序控制结构 40
2.1 为什么需要不同的数据类型 41
2.2 Python中的基本数据类型 42
2.2.1 数值型(Number) 42
2.2.2 布尔类型(Boolean) 45
2.2.3 字符串型(String) 45
2.2.4 列表(List) 49
2.2.5 元组(Tuple) 59
2.2.6 字典(Dictionary) 62
2.2.7 集合(Set) 65
2.3 程序控制结构 67
2.3.1 回顾那段难忘的历史 67
2.3.2顺序结构 69
2.3.3选择结构 70
2.3.4循环结构 74
2.4 高效的推导式 80
2.4.1 列表推导式 80
2.4.2 字典推导式 83
2.4.3 集合推导式 83
2.5 本章小结 84
2.6 思考与提高 84
第3章 自建Python模块与第三方模块 90
3.1 导入Python标准库 91
3.2 编写自己的模块 93
3.3 模块的搜索路径 97
3.4 创建模块包 100
3.5 常用的内建模块 103
3.5.1collection模块 103
3.5.2 datetime模块 110
3.5.3 json模块 115
3.5.4 random模块 118
3.6 本章小结 121
3.7 思考与提高 122
第4章 Python函数 124
4.1 Python中的函数 125
4.1.1 函数的定义 125
4.1.2 函数返回多个值 127
4.1.3函数文档的构建 128
4.2 函数参数的“花式”传递 132
4.2.1 关键字参数 132
4.2.2 可变参数 133
4.2.3 默认参数 136
4.2.4 参数序列的打包与解包 138
4.2.5 传值还是传引用 142
4.3 函数的递归 146
4.3.1感性认识递归 146
4.3.2思维与递归思维 148
4.3.3递归调用的函数 149
4.4 函数式编程的高阶函数 151
4.4.1 lambda表达式 152
4.4.2filter()函数 153
4.4.3map()函数 155
4.4.4reduce()函数 157
4.4.5sorted()函数 158
4.5本章小结 159
4.6思考与提高 160
第5章 Python高级特性 165
5.1 面向对象程序设计 166
5.1.1 面向过程与面向对象之辩 166
5.1.2类的定义与使用 169
5.1.3类的继承 173
5.2 生成器与迭代器 176
5.2.1生成器 176
5.2.2迭代器 183
5.3文件操作 187
5.3.1打开文件 187
5.3.2读取一行与读取全部行 191
5.3.3写入文件 193
5.4 异常处理 193
5.4.1感性认识程序中的异常 194
5.4.2异常处理的三步走 195
5.5错误调试 197
5.5.1利用print()输出观察变量 197
5.5.2assert断言 198
5.6 本章小结 201
5.7 思考与提高 202
第6章 NumPy向量计算 204
6.1 为何需要NumPy 205
6.2 如何导入NumPy 205
6.3生成NumPy数组 206
6.3.1 利用序列生成 206
6.3.2 利用特定函数生成 207
6.3.3Numpy数组的其他常用函数 209
6.4 N维数组的属性 212
6.5NumPy数组中的运算 215
6.5.1向量运算 216
6.5.2算术运算 216
6.5.3逐元素运算与张量点乘运算 218
6.6 爱因斯坦求和约定 222
6.6.1 不一样的标记法 222
6.6.2 NumPy中的einsum()方法 224
6.7NumPy中的“轴”方向 231
6.8操作数组元素 234
6.8.1通过索引访问数组元素 234
6.8.2NumPy中的切片访问 236
6.8.3二维数组的转置与展平 238
6.9NumPy中的广播 239
6.10NumPy数组的高级索引 242
6.10.1“花式”索引 242
6.10.2布尔索引 247
6.11数组的堆叠操作 249
6.11.1水平方向堆叠hstack() 250
6.11.2垂直方向堆叠vstack() 251
6.11.3深度方向堆叠hstack() 252
6.11.4列堆叠与行堆叠 255
6.11.5数组的分割操作 257
6.12NumPy中的随机数模块 264
6.13本章小结 266
6.14思考与提高 267
第7章 Pandas数据分析 271
7.1Pandas简介 272
7.2Pandas的安装 272
7.3Series类型数据 273
7.3.1Series的创建 273
7.3.2Series中的数据访问 277
7.3.3Series中的向量化操作与布尔索引 280
7.3.4Series中的切片操作 283
7.3.5Series中的缺失值 284
7.3.6Series中的删除与添加操作 286
7.3.7Series中的name属性 288
7.4DataFrame类型数据 289
7.4.1构建DataFrame 289
7.4.2访问DataFrame中的列与行 293
7.4.3DataFrame中的删除操作 298
7.4.4DataFrame中的“轴”方向 301
7.4.5DataFrame中的添加操作 303
7.5基于Pandas的文件读取与分析 310
7.5.1利用Pandas读取文件 311
7.5.2DataFrame中的常用属性 312
7.5.3DataFrame中的常用方法 314
7.5.4DataFrame的条件过滤 318
7.5.5DataFrame的切片操作 320
7.5.6DataFrame的排序操作 323
7.5.7Pandas的聚合和分组运算 325
7.5.8DataFrame的透视表 334
7.5.9DataFrame的类SQL操作 339
7.5.10DataFrame中的数据清洗方法 341
7.6泰坦尼克幸存者数据预处理 342
7.6.1数据集简介 342
7.6.2数据集的拼接 344
7.6.3缺失值的处理 350
7.7本章小结 353
7.8思考与提高 353
第8章 Matplotlib与Seaborn可视化分析 365
8.1Matplotlib与图形绘制 366
8.2绘制简单图形 366
8.3pyplot的高级功能 371
8.3.1添加图例与注释 371
8.3.2设置图形标题及坐标轴 374
8.3.3添加网格线 378
8.3.4绘制多个子图 380
8.3.5Axes与Subplot的区别 382
8.4散点图 388
8.5条形图与直方图 392
8.5.1垂直条形图 392
8.5.2水平条形图 394
8.5.3并列条形图 395
8.5.4叠加条形图 400
8.5.5直方图 402
8.6饼图 407
8.7箱形图 409
8.8误差条 411
8.9绘制三维图形 413
8.10与Pandas协作绘图—以谷歌流感趋势数据为例 416
8.10.1谷歌流感趋势数据描述 416
8.10.2导入数据与数据预处理 417
8.10.3绘制时序曲线图 421
8.10.4选择合适的数据可视化表达 423
8.10.5基于条件判断的图形绘制 427
8.10.6绘制多个子图 430
8.11惊艳的Seaborn 431
8.11.1pairplot(对图) 432
8.11.2heatmap(热力图) 434
8.11.3boxplot(箱形图) 436
8.11.4violinplot(小提琴图) 442
8.11.5DensityPlot(密度图) 446
8.12本章小结 450
8.13思考与提高 450
第9章 机器学习初步 459
9.1机器学习定义 460
9.1.1 什么是机器学习 460
9.1.2机器学习的三个步骤 461
9.1.3传统编程与机器学习的差别 464
9.1.4为什么机器学习不容易 465
9.2 监督学习 467
9.2.1 感性认识监督学习 467
9.2.2 监督学习的形式化描述 468
9.2.3损失函数 470
9.3 非监督学习 471
9.4 半监督学习 473
9.5机器学习的哲学视角 474
9.6模型性能评估 476
9.6.1经验误差与测试误差 476
9.6.2过拟合与欠拟合 477
9.6.3模型选择与数据拟合 479
9.7性能度量 480
9.7.1 二分类的混淆矩阵 480
9.7.2查全率、查准率与F1分数 481
9.7.3P-R曲线 484
9.7.4ROC曲线 485
9.7.5AUC 489
9.8 本章小结 489
9.9 思考与提高 490
第10章 sklearn与经典机器学习算法 492
10.1机器学习的利器—sklearn 493
10.1.1sklearn简介 494
10.1.2sklearn的安装 496
10.2线性回归 497
10.2.1 线性回归的概念 497
10.2.2使用sklearn实现波士顿房价预测 499
10.3 k-近邻算法 516
10.3.1算法简介 516
10.3.2 k值的选取 518
10.3.3 特征数据的归一化 519
10.3.4 邻居距离的度量 521
10.3.5分类原则的制定 522
10.3.6 基于sklearn的k-近邻算法实战 522
10.4Logistic回归 527
10.4.1为什么需要Logistic回归 527
10.4.2Logistic源头初探 529
10.4.3Logistic回归实战 532
10.5神经网络学习算法 536
10.5.1人工神经网络的定义 537
10.5.2神经网络中的“学习”本质 537
10.5.3神经网络结构的设计 540
10.5.4利用sklearn搭建多层神经网络 541
10.6非监督学习的代表—k均值聚类 550
10.6.1聚类的基本概念 551
10.6.2簇的划分 552
10.6.3k均值聚类算法核心 552
10.6.4k均值聚类算法优缺点 554
10.6.5基于sklearn的k均值聚类算法实战 555
10.7本章小结 561
10.8思考与提高 562
相关资源










编程语言与程序设计
Python编程 从入门到实践 第3版(图灵出品)
编程语言与程序设计
Hello算法(图灵出品)

编程语言与程序设计
C++ Primer Plus 第6版 中文版(异步图书出品)



编程语言与程序设计
C++ Primer(中文版 第5版)(博文视点出品)


编程语言与程序设计
高效C/C++调试









