
本站推荐







书籍资料
- 内容简介
- 作者介绍
- 书籍目录
《亿级流量系统架构设计与实战》的适用人群包括计算机相关专业的学生、希望寻求大厂软件开发工程师岗位的求职者,以及各信息技术类公司的后台研发工程师、架构师和技术管理人员。
资深后台研发工程师,拥有8年互联网后台研发经验,现任某全球社交产品后台子方向负责人。从事互联网社交产品领域的研发与架构设计工作多年,从业以来负责过多个知名产品的后台开发工作,相继深耕于消息队列、服务发现系统、服务治理、分布式事务、高并发架构设计、全球多活等技术领域。
第1章大型互联网公司的基础架构 2
1.1引言:单机房的内部架构 2
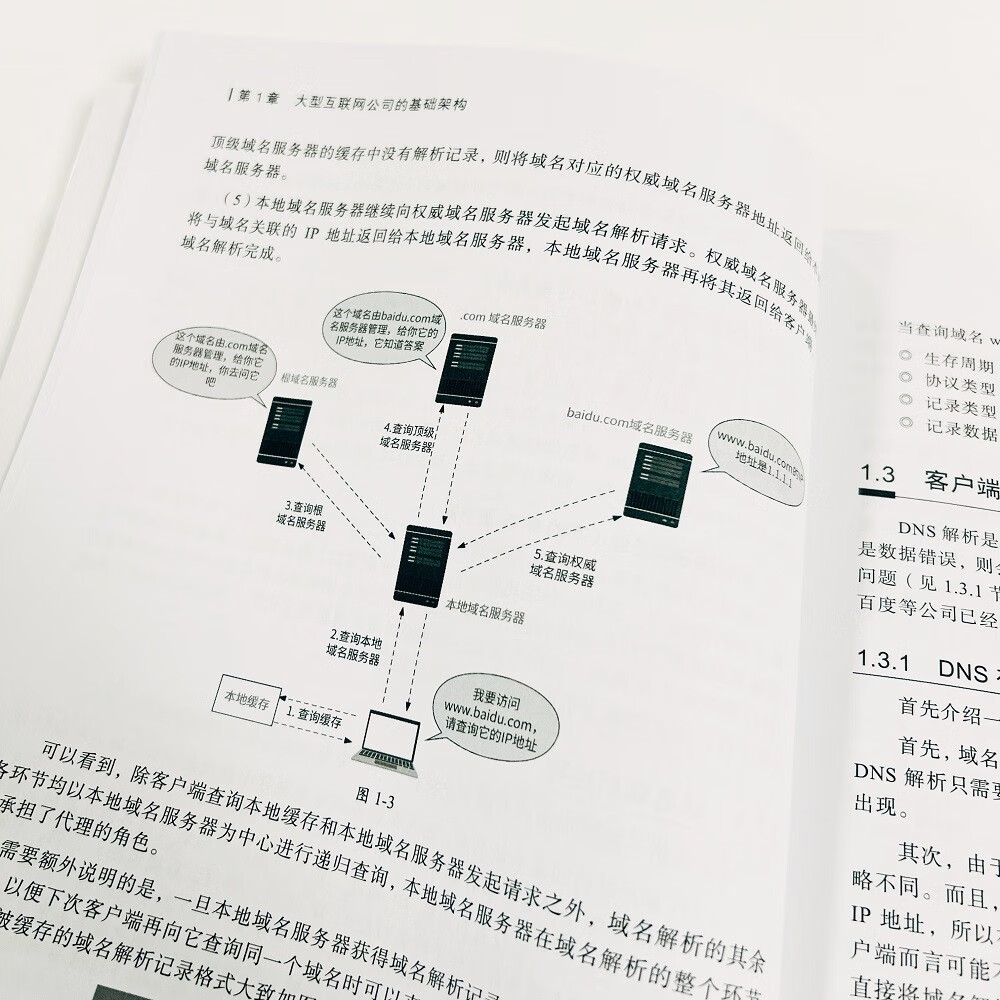
1.2客户端连接机房的技术1:DNS 5
1.2.1DNS的意义 5
1.2.2域名结构 6
1.2.3域名服务器 6
1.2.4域名解析过程 7
1.3客户端连接机房的技术2:HTTPDNS 9
1.3.1DNS存在的问题 9
1.3.2HTTPDNS的原理 10
1.3.3HTTPDNS实践 11
1.4接入层的技术演进 12
1.4.1Nginx 13
1.4.2LVS 19
1.4.3LVS+Nginx接入层的架构 25
1.5服务发现 28
1.5.1注册与发现 29
1.5.2可用地址管理 30
1.5.3地址变更推送 31
1.6RPC服务 32
1.7存储层技术:MySQL 35
1.7.1关系型数据库 35
1.7.2MySQL的优势 37
1
7.3高可用架构1:主从模式 37
1.7.4高可用架构2:MHA 40
1.7.5高可用架构3:MMM 41
1.7.6高可用架构4:MGR 43
1.8存储层技术:Redis 44
1.8.1高可用架构1:主从模式 44
1.8.2高可用架构2:哨兵模式 45
1.8.3高可用架构3:集群模式 46
1.8.4高可用架构4:中心化集群架构 50
1.9存储层技术:LSMTree 53
1.9.1LSMTree的原理 53
1.9.2读/写数据的流程 56
1.10存储层技术:其他NoSQL数据库 57
1.11消息中间件技术 61
1.11.1通信模式与用途 62
1.11.2Kafka的重要概念和原理 64
1.11.3Kafka的高可用 67
1.12多机房:主备机房 69
1.13多机房:同城双活 71
1.13.1存储层改造 71
1.13.2灵活实施 73
1.13.3分流与故障切流 74
1.13.4两地三中心 77
1.14多机房:异地多活 78
1.14.1架构要点 78
1.14.2MySQLDRC的原理 80
1.14.3RedisDRC的原理 83
1.14.4分流策略 84
1.14.5数据复制链路 85
1.15本章小结 86
第2章通用的高并发架构设计 88
2.1高并发架构设计的要点 88
2.1.1形成高并发系统的必要条件 88
2.1.2高并发系统的衡量指标 89
2.1.3高并发场景分类 90
2.2高并发读场景方案1:数据库读/写分离 91
2.2.1读/写分离架构 91
2.2.2读/写请求路由方式 91
2.2.3主从延迟与解决方案 92
2.3高并发读场景方案2:本地缓存 93
2.3.1基本的缓存淘汰策略 93
2.3.2W-TinyLFU策略 94
2.3.3缓存击穿与SingleFlight 95
2.4高并发读场景方案3:分布式缓存 100
2.4.1分布式缓存选型 100
2.4.2如何使用Redis缓存 101
2.4.3缓存穿透 102
2.4.4缓存雪崩 103
2.4.5缓存更新 103
2.5高并发读场景总结:CQRS 105
2.5.1CQRS的简要架构与实现 106
2.5.2更多的使用场景 107
2.5.3CQRS架构的特点 108
2.6高并发写场景方案1:数据分片之数据库分库分表 108
2.6.1分库和分表 109
2.6.2垂直拆分 109
2.6.3水平拆分 111
2.6.4水平拆分规则 113
2.6.5扩容方案 117
2.6.6其他数据分片形式 120
2.7高并发写场景方案2:异步写与写聚合 120
2.7.1异步写 121
2.7.2写聚合 122
2.8本章小结 122
第3章通用的服务可用性治理手段 124
3.1微服务架构与网络调用 124
3.2重试 126
3.2.1幂等接口 126
3.2.2重试时机 130
3.2.3重试风险与重试风暴 130
3.2.4重试控制:不重试的请求 131
3.2.5重试控制:重试请求比 132
3.3熔断与隔离 132
3.3.1服务雪崩 133
3.3.2Hystrix熔断器 134
3.3.3Resilience4j和Sentinel熔断器 136
3.3.4共享资源与舱壁隔离 137
3.3.5舱壁隔离的实现 138
3.4限流 139
3.4.1频控 140
3.4.2单机限流1:时间窗口 141
3.4.3单机限流2:漏桶算法 143
3.4.4单机限流3:令牌桶算法 144
3.4.5全局限流 146
3.5自适应限流 148
3.5.1服务与等待队列 149
3.5.2基于请求排队时间 150
3.5.3基于延迟比率 151
3.5.4其他方案 152
3.6降级策略 155
3.6.1服务依赖度降级 155
3.6.2读请求降级 158
3.6.3写请求降级 159
3.7本章小结 160
基础服务设计篇
第4章唯一ID生成器 164
4.1分布式唯一ID 164
4.1.1全局唯一与UUID 164
4.1.2唯一ID生成器的特点 165
4.1.3单调递增与趋势递增 167
4.2单调递增的唯一ID 168
4.2.1RedisINCRBY命令 168
4.2.2基于数据库的自增主键 171
4.2.3高可用架构 172
4.3趋势递增的唯一ID:基于时间戳 174
4.3.1正确使用时间戳 174
4.3.2Snowflake算法的原理 175
4.3.3Snowflake算法的灵活应用 175
4.3.4分配服务实例ID 177
4.3.5时钟回拨问题与解决方案 179
4.3.6最终架构 179
4.4趋势递增的唯一ID:基于数据库的自增主键 180
4.4.1分库分表架构 181
4.4.2批量缓存架构 182
4.5美团点评开源方案:Leaf 183
4.5.1Leaf-segment方案 183
4.5.2Leaf-snowflake方案 185
4.6本章小结 187
第5章用户登录服务 189
5.1用户账号 189
5.2用户登录服务的功能要点 190
5.3密码保护 192
5.3.1使用HTTPS通信 192
5.3.2非对称加密 193
5.3.3密码加密存储 194
5.4手机号登录和邮箱登录 194
5.4.1数据表设计 195
5.4.2用户注册 195
5.4.3用户登录 196
5.4.4手机号一键登录 197
5.5第三方登录 199
5.5.1OAuth2标准 200
5.5.2客户端接入第三方登录 201
5.5.3服务端接入第三方登录 201
5.5.4第三方登录的完整流程总结 203
5.6登录态管理 204
5.6.1存储型方案:Session 205
5.6.2计算型方案:令牌 207
5.6.3长短令牌方案 208
5.7扫码登录 210
5.7.1二维码 210
5.7.2扫码登录的场景介绍 211
5.7.3扫码登录的技术实现 211
5.8本章小结 213
第6章海量推送系统 215
6.1分布式长连接服务的技术要素分析 216
6.1.1WebSocket协议简介 216
6.1.2长连接服务器 217
6.1.3分布式推送服务器 218
6.1.4路由算法 219
6.2海量推送系统设计 220
6.2.1整体架构设计 220
6.2.2长连接的建立过程 221
6.2.3消息格式设计 222
6.2.4消息推送接口 223
6.2.5单点消息推送的细节 224
6.2.6全局消息推送的细节 225
6.2.7多点消息推送的细节 226
6.2.8pusher平滑升级的问题 227
6.2.9pusher扩容的问题 236
6.3本章小结 237
核心服务设计篇
第7章内容发布系统 240
7.1内容发布系统的设计背景 240
7.2内容存储设计 241
7.2.1内容数据的存储 241
7.2.2内容元信息的存储 243
7.2.3内容主体的存储选型 244
7.2.4音视频转码 245
7.3内容审核设计 246
7.3.1内容审核的必要性 246
7.3.2内容审核的时机策略 246
7.3.3如何审核内容 247
7.3.4审核中心的对外交互 249
7.4内容的全生命周期管理设计 250
7.4.1内容的创建设计 250
7.4.2内容的修改设计 252
7.4.3内容审核结果处理与版本控制设计 254
7.4.4内容的删除与下架设计 256
7.5内容分发设计 256
7.5.1内容分发渠道 257
7.5.2何时通知分发渠道 257
7.5.3将内容投递到分发渠道 257
7.6内容展示设计 259
7.6.1内容数据的特点 259
7.6.2使用CDN加速静态资源访问 259
7.6.3使用缓存和多副本支撑高并发读取 260
7.6.4内容展示流程设计 263
7.7完整架构总览 265
7.8本章小结 267
第8章通用计数系统 268
8.1计数的常见用途 268
8.2如何存储计数数据 269
8.2.1计数数据的特点 269
8.2.2关系型数据库的困境 270
8.2.3是否要使用关系型数据库 270
8.2.4使用Redis存储计数数据 271
8.3海量计数服务设计 272
8.3.1Redis数据类型 272
8.3.2计数累计与读取的示例 274
8.3.3优化内存的调研 274
8.3.4优化内存:定制化Redis 276
8.3.5冷热数据分离 279
8.3.6应对过热数据 280
8.3.7计数服务架构图 281
8.3.8计数服务的适用范围 282
8.4本章小结 283
第9章排行榜服务 284
9.1排行榜的应用场景 284
9.2排行榜技术的特点 285
9.3使用Redis实现排行榜 285
9.3.1使用RedisZSET 286
9.3.2幂等更新 287
9.3.3同积分排名处理 289
9.3.4服务设计 291
9.3.5关于大Key的问题 295
9.4粗估排行榜的实现 296
9.4.1线段树 296
9.4.2粗估排名的实现 299
9.5精确排名与粗估排名结合 306
9.6本章小结 309
第10章用户关系服务 310
10.1用户关系服务的职责 310
10.2基于RedisZSET的设计 311
10.3基于数据库的设计 312
10.3.1最初的想法 312
10.3.2应对分库分表 313
10.3.3Following表的索引设计 314
10.3.4Follower表的索引设计 316
10.3.5进阶:回表问题与优化 316
10.3.6关注数和粉丝数 317
10.4缓存查询 318
10.4.1缓存什么数据 318
10.4.2缓存的创建与更新策略 319
10.4.3本地缓存 321
10.4.4缓存与数据库结合的最终方案 321
10.5基于图数据库的设计 323
10.5.1实现用户关系 323
10.5.2应用权衡 327
10.6本章小结 328
第11章TimelineFeed服务 330
11.1Feed流的分类 330
11.2TimelineFeed流的功能特性 331
11.3拉模式与用户发件箱 331
11.4推模式与用户收件箱 333
11.5推拉结合模式 334
11.5.1结合思路 334
11.5.2区分活跃用户 335
11.6实现TimelineFeed服务的关键技术细节 336
11.6.1内容与用户收件箱的交互 336
11.6.2推送子任务 338
11.6.3收件箱保存什么数据 339
11.6.4读请求参数 340
11.6.5使用数据库实现收件箱 340
11.6.6使用RedisZSET实现收件箱 343
11.6.7通过推拉结合模式构建TimelineFeed数据 348
11.6.8收尾工作 355
11.7本章小结 356
第12章评论服务 357
12.1评论功能 357
12.2评论列表模式 358
12.3评论服务设计的初步想法 361
12.4单级模式服务设计 361
12.4.1数据表的初步设计 361
12.4.2读/写接口与索引 362
12.4.3数据库的最终设计 363
12.4.4高并发问题 364
12.5盖楼模式服务设计 366
12.5.1数据库方案:递归查询 366
12.5.2数据库方案:保存完整楼层 368
12.5.3图数据库方案 369
12.6二级模式服务设计 370
12.6.1一级评论和二级评论 370
12.6.2时间顺序:数据库方案 371
12.6.3时间顺序:图数据库方案 373
12.6.4评论审核与状态 376
12.6.5按照热度排序 377
12.6.6高并发处理 381
12.6.7架构总览 385
12.7本章小结 386
第13章IM服务 388
13.1IM的意义与核心能力 388
13.2IM相关概念 389
13.3消息投递 390
13.3.1存储消息:读扩散与写扩散 390
13.3.2接收消息:拉模式与推模式 393
13.4存储初探 395
13.5消息的有序性保证 396
13.5.1消息乱序 396
13.5.2客户端发送消息 396
13.5.3服务端存储消息 397
13.5.4服务端推送消息与客户端补偿 398
13.6会话管理与命令消息 401
13.6.1创建单聊会话 402
13.6.2创建群聊会话 402
13.6.3命令消息 403
13.7消息回执 404
13.7.1上报已读消息 404
13.7.2记录已读消息 404
13.8阶段性汇总:存储设计 405
13.9高并发架构 408
13.9.1发送消息 409
13.9.2数据缓存 409
13.9.3消息分级 410
13.9.4直播间弹幕模式 411
13.10本章小结:最终架构 413
相关资源
 编程不难(全彩图解 + 微课 + Python编程)(鸢尾花数学大系:从加减乘除到机器学习)
2026-05-11
编程不难(全彩图解 + 微课 + Python编程)(鸢尾花数学大系:从加减乘除到机器学习)
2026-05-11
























